






Em alguns de seus modelos FAS e V-Series, a NetApp fornece uma funcionalidade avançada para armazenamento de dados em alta disponilibilidade e com espelhamento síncrono chamada MetroCluster. Esse artigo discute as diferenças e vantagens da utilização do MetroCluster em relação a um par de HA tradicional ou a um par de HA com espelhamento síncrono (outras funcionalidades também fornecidas pela NetApp).
Um par de HA é formado por dois nós de storage cujas controladoras estão conectadas entre si diretamente ou através de switches Fibre Channel (os modelos de conexão variam de acordo com a distância pretendida entre os nós e tem requisições de hardware adicional diferentes).
Em uma configuração de HA, um nó pode assumir as funções do outro nó caso este fique indisponível. Cada nó monitora continuamente o seu parceiro de HA, espelhando de forma síncrona (nos casos em que o espelhamento síncrono é utilizado) o conteúdo da sua memória não volátil (NVRAM ou NVMEM), promovendo tolerância a falhas e permitindo a execução de operações não-disruptivas (tais como upgrades e manutenção de hardware ou software).
Porém, em um par tradicional de HA, cada nó controla seus próprios discos ou arrays de LUN. Em caso de falha de um nó, o parceiro de HA assume o acesso de leitura e escrita dos discos do nó indisponível.
Os pares de HA com espelhamento síncrono tem a vantagem de manterem duas cópias completas dos dados que são continuamente sincronizadas cada vez que o sistema Data ONTAP realiza uma escrita em um agregado de discos espelhado. Porém, com o par de HA em espelhamento síncrono não é possível que o failover para o site secundário ocorra na falha completa de um nó no site primário (incluindo a falha de seu storage). Para tal funcionalidade, é necessário utilizar a configuração de MetroCluster com SyncMirror.
A funcionalidade MetroCluster da NetApp estende a alta disponibilidade promovendo uma camada adicional de proteção para casos extremamente críticos, onde o espelhamento síncrono promove 0% de perda de dados e o failover automático garante praticamente 100% de disponibilidade (promovendo um RPO de 0 e um RTO de quase 0).
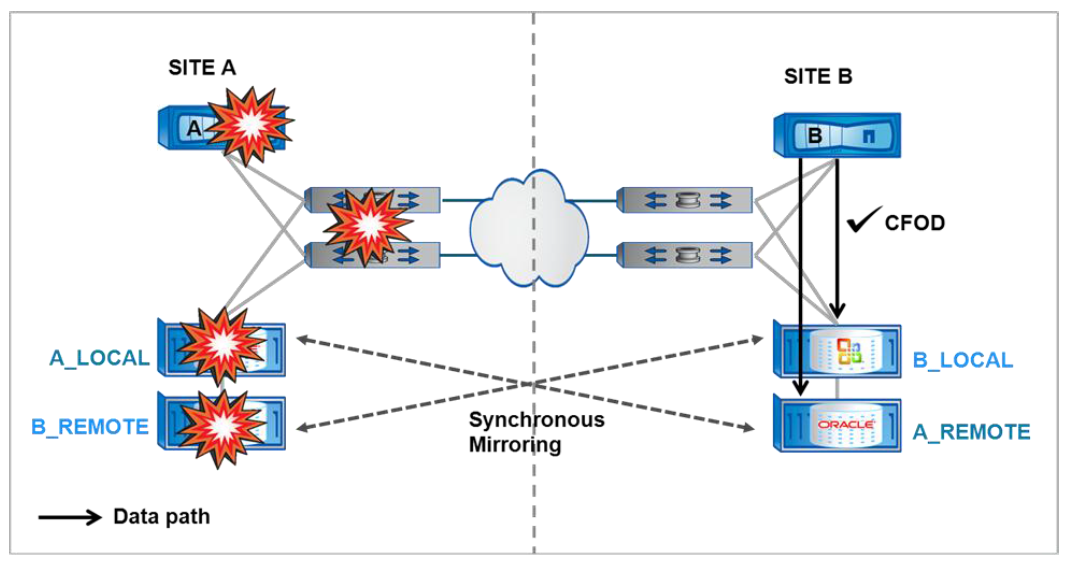
O SyncMirror da Netapp espelha dados de forma síncrona para os pares do MetroCluster escrevendo os dados no storage local (que está servindo os dados) e no storage remoto (que normalmente não está servindo dados, apesar de que o MetroCluster permite que o storage remoto sirva dados também, funcionalidade que pode aumentar a performance de leitura em algumas situações).
Se o storage local falhar (o exemplo mais extremo seria a falha completa do site principal), o parceiro de HA do MetroCluster assume a operação de servir os dados e nenhuma perda de dados acontece, uma vez que a replicação dos dados ocorre de forma síncrona.
Configurações em MetroCluster oferecem as mesmas vantagens do espelhamento síncrono de pares em HA com a vantagem adicional de permitir o failover se um site inteiro falhar (como por exemplo em um desastre natural ou em uma falha completa de energia no site principal).
O MetroCluster promove uma forma simples de fazer a virada para o site secundário em casos de desastre, uma vez que não é necessário interromper manualmente o espelhamento dos discos e subir os volumes no site secundário. A partir da declaração do desastre, um único comando ordena a virada e disponibiliza os dados no storage secundário.
Nas arquiteturas de MetroCluster toda a estrutura deve ser montada de forma redundante (controladoras, discos, cabeamento, switches, adaptadores, etc) e é muito importante consultar a matriz de interoperabilidade no website do fabricante.
O MetroCluster permite dois tipos de configuração:
- Para distâncias até 500 metros fibras multimodo são utilizadas para conectar as controladoras diretamente (Stretch MetroCluster).
- Para distâncias entre 500 metros e 200 quilômetros são utilizados switches Fibre Channel para interconectar os storages (Fabric MetroCluster). Existem opções de configuração tanto para determinados switches Brocade quanto para switches Cisco. A mídia a ser utilizada neste caso é o DWDM. A recomendação é que tanto os switches Fibre Channel quanto os enlaces de interconexão sejam utilizados de forma exclusiva (sem compartilhamento para outros serviços).
Na configuração discutida, para evitar cenários de split-brain (onde a comunicação entre os dois sites é perdida mas ambos os storages continuam em funcionamento), a declaração do desastre deve ocorrer com intervenção humana e um comando de failover deve ser aplicado de forma manual (só um comando basta para que os dados sejam servidos a partir do site secundário).
Isso ocorre porque normalmente o MetroCluster não consegue diferenciar entre a falha completa de um site ou a perda de conectividade entre os sites (como em outras plataformas).
O failover manual só se aplica para o cenário de desastre completo, uma vez que em casos de falhas simples de componentes (falha de controladora, falha de gaveta, falha de switch) o failover ocorre de forma automática.
No entanto, se for desejável criar um cenário completamente automatizado, é possível utilizar uma funcionalidade chamada MetroCluster Tie-Breaker (MCTB) em um terceiro site. O MCTB monitora continuamente as atividades dos nós no site principal e secundário e decide automaticamente se o failover é necessário.
O MetroCluster em modo stretch permite RPO zero e RTO próximo a zero em distâncias de campus (até 500 metros) e em modo fabric attached possibilita o mesmo nível de disponibilidade e operação contínua em distâncias metropolitanas (até 200 Km).
Uma outra arquitetura opcional combinando MetroCluster e a funcionalidade de replicação assíncrona da NetApp (SnapMirror) pode criar a possibilidade de estender a alta disponibilidade da solução também para distâncias regionais com a criação um terceiro site de contingência, promovendo uma arquitetura de DR ainda mais robusta.
 Entre em Contato
Entre em Contato