






O vCenter Operations Manager é uma aplicação que gerencia a saúde, a capacidade e a performance de um ambiente virtualizado com a plataforma da VMware.
O Operations Manager permite monitorar de perto o ambiente virtualizado, possibilitando um gerenciamento proativo do ambiente para garantir SLAs acordados, além de permitir otimização da performance e análise de riscos da estrutura.
Ele também facilita a análise de problemas no ambiente virtualizado e a criação de cenários (what-if) para que sejam observados os impactos de determinadas alterações na estrutura antes que elas sejam implementadas.
A ferramenta ajuda a integrar a estrutura de virtualização com processos de TI tais como Gerência de Mudanças, Gerência de Incidentes, Controle de Configuração, dentre outros.
Em três edições (Standard, Advanced e Enterprise Editions), a aplicação é distribuída em formato standalone ou como vApp. O modelo de licenciamento é demonstrado pela figura abaixo:

O vCenter Operations Manager pode ser acessado com o cliente do vSphere (através de um plugin) ou pelo portal de administração Web da própria ferramenta.
O Agility Tech Center testou a aplicação em seu laboratório no format vApp.
Nota 1: No VMworld 2013 em Barcelona, a VMware anunciou que a versão 5.8 do Operations Manager irá prover suporte de monitoração também para a plataforma Hyper-V.
Nota 2: uma vApp possui o mesmo tipo de operação de uma máquina virtual, porém pode conter múltiplas máquinas virtuais ou appliances.
Componentes da vAPP do Operations Manager
O vCenter Operations Manager no format vApp é constituído por duas máquinas virtuais: a Analytics VM e a UI VM. Entender o papel dessas máquinas virtuais ajuda a conhecer a arquitetura do Operations Manager.
Analytics VM
Essa VM é responsável por coletar dados do vCenter, vCenter Configurations Manager e de ferramentas de terceiros que possuem integração com o Operations Manager (métricas, topologia e eventos). Seus componentes estão descritos a seguir:
- Algoritmos para análise de performance e capacidade
- Capacity Collector que recebe as métricas e realiza a computação de métricas derivadas
- Análise em tempo real das métricas recebidas, geração de alertas e atualização de pontuações dos marcadores (badges)
- Banco de dados para armazenar as estatísticas das métricas coletadas (FSDB)
- Banco de dados Postgres DB para armazenar o restante dos dados coletados, tais como objetos, relacionamentos, eventos, thresholds dinâmicos e alertas.
UI VM
Essa máquina virtual permite a visualização gráfica da análises realizadas pela Analytics VM em forma de marcadores (badges) e sistemas de pontuação através de uma interface Web.
Funcionalidades do Operations Manager
O vCenter Operations Manager coleta dados de performance de objetos em cada nível do ambiente virtualizado, desde máquinas virtuais até clusters ou data centers. A ferramenta fornece informações em tempo real sobre problemas existentes ou potenciais em diversas partes do ambiente.
A ferramenta traz as seguintes funcionalidades:
- Combinação de métricas em sistemas de pontuação para a saúde, eficiência e riscos do ambiente ou objeto analisado.
- Cálculo da faixa de comportamento normal para cada métrica, mostrando também desvios de padrão.
- Utilização de limiares dinâmicos (dynamic thresholds) que permitem melhorar a definição dos valores tidos como normais para o ambiente à medida em que mais dados são coletados.
- Representação gráfica dos estados atual e passado de todo o ambiente virtual ou de partes dele.
- Visualização de informações relativas a alterações na hierarquia do ambiente virtualizado (por exemplo, quando da movimentação de uma VM de host, é possível entender como a alteração afetou os objetos envolvidos).
- Permite a criação de grupos de objetos para a organização da monitoração de acordo com a estrutura ou política da organização.
Métricas e Dynamic Thresholds
O Operations Manager coleta diversos tipos de dados, ou atributos, para cada objeto no inventário do vCenter e os consolida em métricas. Os dados são coletados em intervalos regulares de tempo e acumulados em indicadores.
O conceito de “normalidade” de um objeto ou ambiente é tratado de forma dinâmica pela ferramenta através dos limiares dinâmicos (que são ajustados continua e automaticamente),
Métricas consideradas normais para uma determinada situação (por exemplo, maior utilização de CPU em um determinado momento do dia) podem indicar problemas em outros casos (alta CPU em um horário em que o ambiente deveria estar ocioso).
Os limiares dinâmicos (dynamic thresholds) adicionam um contexto às métricas que permite que o Operations Manager possa distinguir se um objeto está operando normalmente ou não e elimina o esforço manual requerido para configurar manualmente limiares para diversas métricas.
Além disso, os limiares dinâmicos tendem a ser mais precisos do que as configurações manuais, pois consideram o estado real da operação do objeto e não estão baseados em configurações arbitrárias. Isso ajuda a eliminar falso-positivos nos alarmes gerados.
Gerência de Falhas
O Operations Manager pode ser utilizado como ferramenta para gerência de falhas do ambiente virtualizado, uma vez que gera alertas quando determinados eventos ocorrem nos objetos monitorados, quando a análise de dados demonstra um desvio dos valores tidos como normais ou quando ocorre um problema em seus próprios componentes que afete sua monitoração (essa última categoria de eventos está incluída nos eventos administrativos).
Os alertas podem ser visualizados no portal de administração ou enviados por email para um administrador configurado na ferramenta. Há também um gráfico de tendência de alertas que pode ser obtido para cada objeto.
Badges
O vCenter Operations Manager utiliza o conceito de badges, que poderiam ser traduzidos como símbolos ou marcadores, para ilustrar as métricas derivadas para cada objeto.
Os badges são divididos em principais e secundários, de forma que a composição dos valores dos badges secundários contribui para o valor do badge primário. Os badges possuem códigos de cores que vão do verde (estado normal), amarelo, laranja ou vermelho.
Os três principais badges são saúde (Health), risco (Risk) e eficiência (Efficiency)
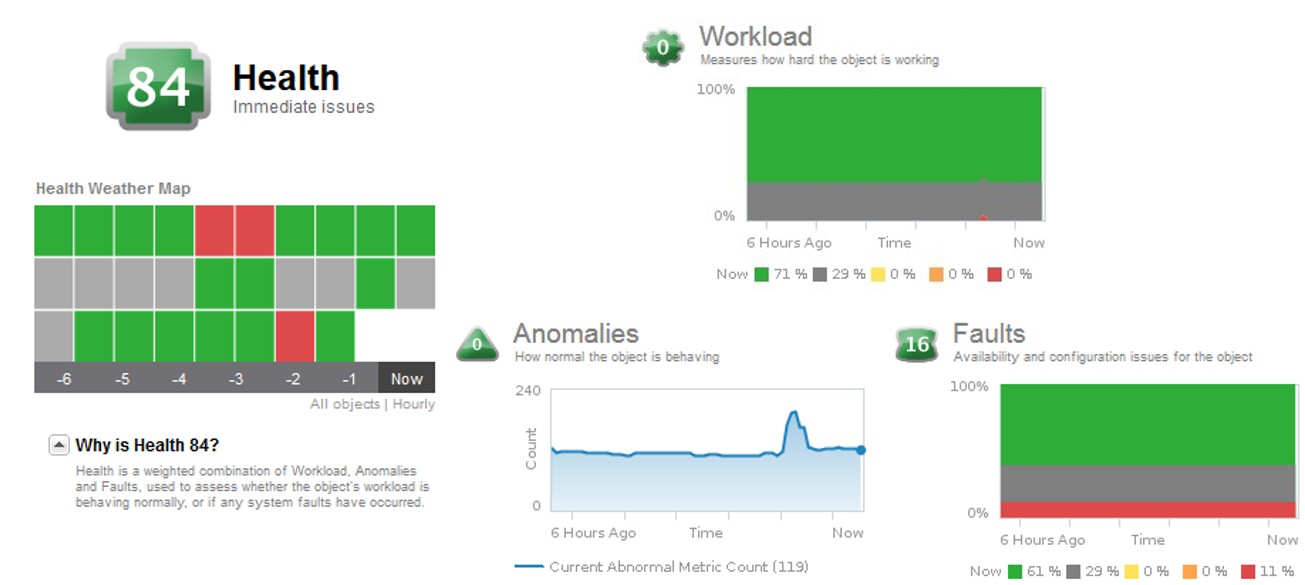
Saúde
O badge de saúde aponta questões a serem tratadas de imediato é calculado de acordo com o resultado das métricas de três badges secundários:
- Anomalias: qual o nível de normalidade que o objeto apresenta
- Carga de trabalho (workload): mede o quanto o objeto está trabalhando
- Faltas: mostra problemas de configuração e disponibilidade do objeto
O conjunto de métricas e badges relacionados à saúde dos objetos é demonstrado pela figura abaixo:
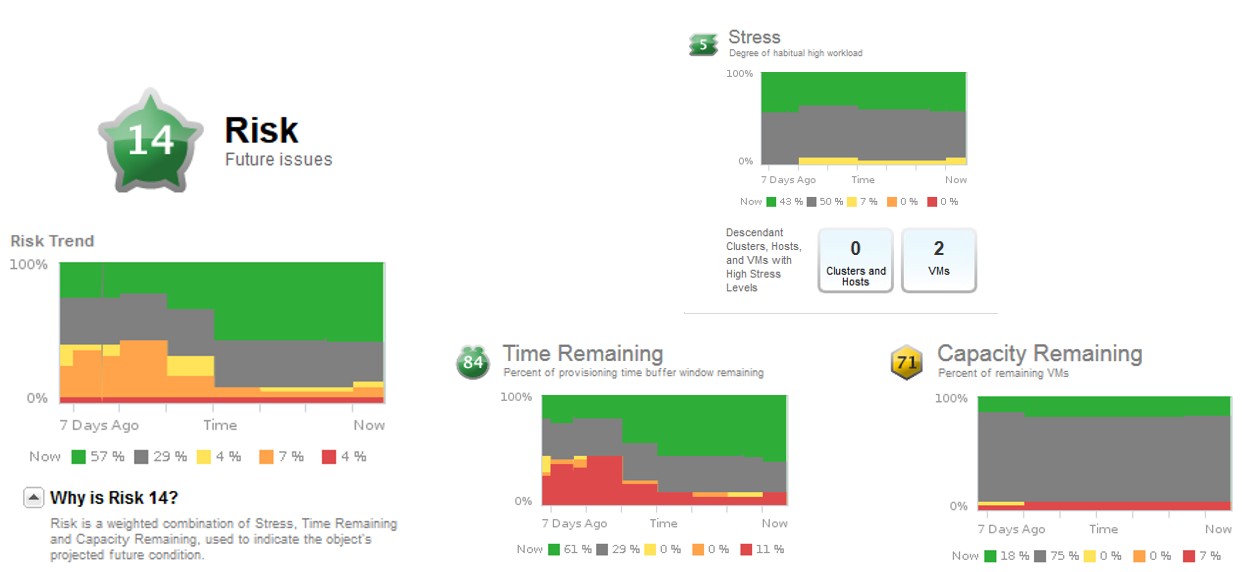
Risco
O badge de risco aponta possíveis questões futuras com o objeto monitorado e é calculado de acordo com o resultado das métricas de três badges secundários:
- Estresse: grau de carga de trabalho habitual e limites históricos de alta carga de trabalho;
- Tempo restante: indica o tempo restante antes que um recurso se esgote;
- Capacidade restante: mostra a quantidade de VMs restante como uma porcentagem do total de capacidade para as VMs.
O conjunto de métricas e badges relacionados ao risco para um objeto é demonstrado pela figura abaixo:
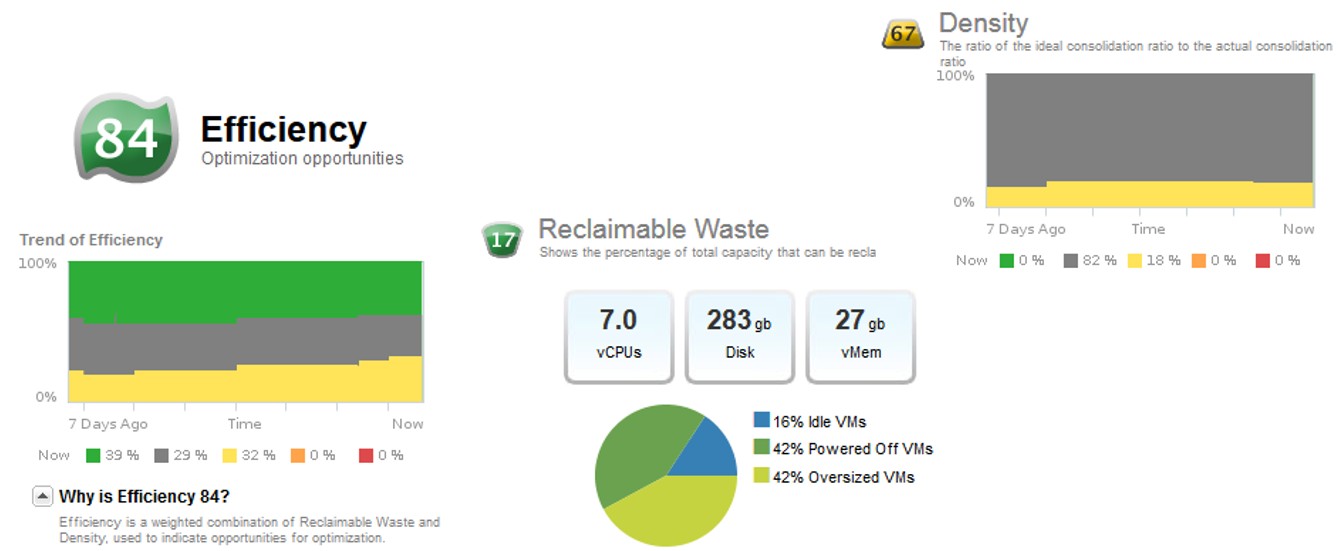
Eficiência
O badge de eficiência aponta oportunidades de otimização de recursos é calculado de acordo com o resultado das métricas de dois badges secundários:
- Lixo reclamável: mostra a porcentagem da capacidade de recursos que pode ser retomada para utilização
- Densidade: mostra a relação entre a razão ideal de consolidação de recursos versus a razão de consolidação existente, em termos de VM por host, vCPU por CPU física e entre vMEM e memória física.
O conjunto de métricas e badges relacionados à eficiência é demonstrado pela figura abaixo:
Referências
Este artigo utiliza como referências testes realizados no laboratório do Agility Tech Center e os seguintes documentos da VMware:
- VMware vCenter Operations Manager Getting Started Guide (versão 5.7)
- vApp Deployment and Configuration Guide (vCenter Operations Manager 5.7)
 Entre em Contato
Entre em Contato