







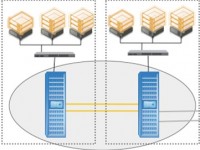
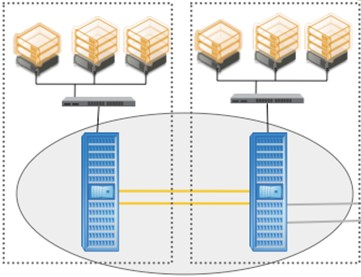
No MetroCluster, em grande parte das falhas, o comportamento do failover e giveback pode ser ajustado através de parâmetros. Esse artigo aborda a configuração de parâmetros relacionados ao HA em configuração de Stretch MetroCluster.
Comando Options
O comando options é usado para configurar diversas opções de software no Data ONTAP. Os parâmetros definidos através desse comando mantém várias funções dos nós, tais como segurança, acesso a arquivos e comunicação de rede. Determinadas opções também alteram o comportamento do par de HA e serão discutidas nesse artigo.
Para configurar parâmetros digitar o seguinte comando:
options [nome do parâmetro] [valor do parâmetro]
Maiores detalhes sobre o comando options podem ser obtidas através do comando:
man options
Diversos parâmetros definidos através do comando options determinam como o takeover ou o giveback irão ocorrer em determinadas situações de falha.
Durante o takeover, determinados valores podem ser sobrescritos pelo nó secundário, então é importante garantir que os parâmetros que devem ser os mesmos em ambos os nós estejam configurados de forma compatível.
Através do comando options você pode verificar se a configuração do parâmetro deve ou não ser igual nos dois nós (através de um comentário após o valor do parâmetro).
Para verificar as opções configuradas e a obrigatoriedade ou não de configuração semelhante nos dois nós, digitar:
options
Os parâmentros que afetam as operações de takeover ou giveback, assim como outras funcionalidades importantes relacionadas ao HA serão discutidas a seguir.
Configurações de Parâmetros para Failover e Giveback
O takeover de um nó pode ocorrer por diversas razões, tais como erros de sistema, perda de alimentação de energia, etc. Em algumas circunstâncias, é possível configurar o takeover automático para o nó secundário em função do tipo de erro ocorrido ou desabilitá-lo para que possa ser efetuado de forma manual. Em determinados tipos de erro, entretanto, o takeover automático irá ocorrer independente de qualquer configuração e não poderá ser evitado.
Na configuração, alguns parâmetros são alterados no nó secundário automaticamente quando configurados no nó primário, em outros casos são permitidas configurações diferentes entre os dois nós.
Nos subitens a seguir serão discutidos os erros e parâmetros relacionados ao failover.
Failover automático obrigatório
A seguintes situações causarão um failover automático independente de qualquer configuração de parâmetros:
- Um nó pára de enviar mensagens de heartbeat para seu parceiro.
- A suspensão da operação do nó primário ocorre através do comando halt sem a opção –f (se a flag –f for incluída, o takeover automático não irá ocorrer.)
- A utilização do comando cf takeover inicia um failover manual independente de qualquer outra configuração utilizada.
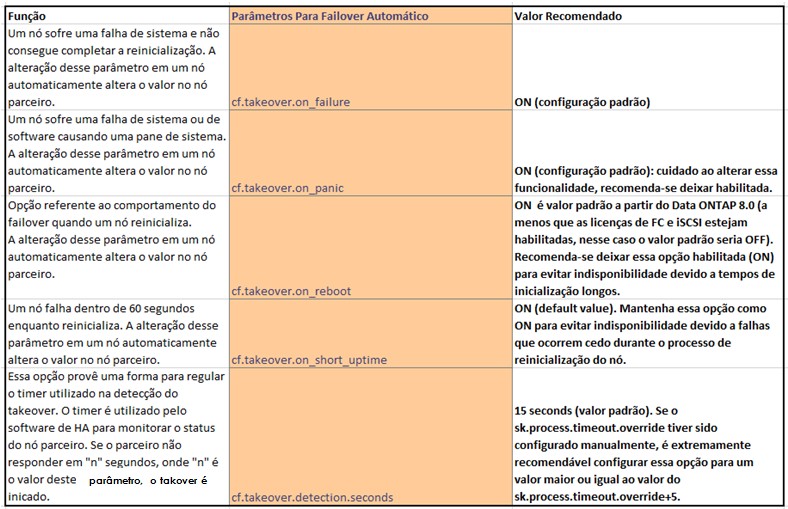
Opções que alteram o comportamento do failover
A seguir as opções que alteram o comportamento do failover para automático ou manual de acordo com o tipo de erro ocorrido, assim como os valores recomendados como melhores práticas de configuração de HA.
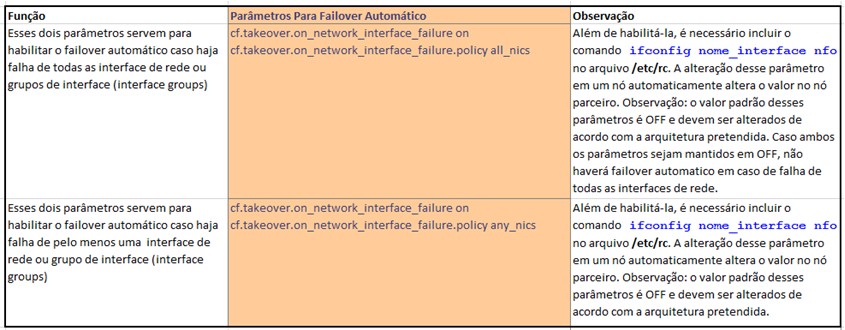
A seguir são consideradas as opções relacionadas à falhas nas interfaces de rede. Os dois parâmetros são utilizados em conjunto para determinar se o failover automático irá ou não ocorrer em função da falha de uma ou mais interfaces de rede.
A configuração desses parâmetros deverá levar em consideração a arquitetura pretendida e principalmente se a funcionalidade de MultiStore está sendo utilizada para abrigar múltiplos clientes. Maiores informações podem ser encontradas na documentação “MultiStore Management Guide” da Netapp.
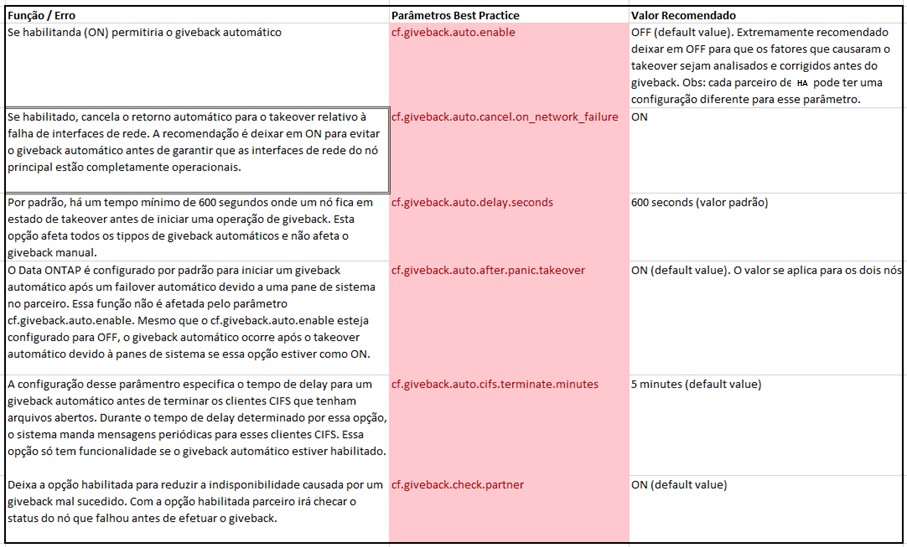
Considerações sobre o Giveback
A automação do giveback é controlada pelo parâmetro cf.giveback.auto.enable.
A recomendação é não habilitar o giveback automático para configurações de MetroCluster, uma vez que, antes que a operação de giveback possa ocorrer, os aggregates devem ser restabelecidos nos dois nós. Se o giveback automático estiver habilitado, esse passo importante para a segurança dos dados não poderá ser realizado.
Caso o takeover automático tenha ocorrido por pane de sistema, o giveback automático irá ocorrer a partir do reestabelecimento do nó principal mesmo que o parâmetro cf.giveback.auto.enable esteja configurado para OFF.
A tabela a seguir demonstras as melhores práticas para configuração dos parâmetros de giveback.
Parâmetro change_fsid
O parâmetro change_fsid altera a forma como os IDs dos volumes e LUNs são apresentados no nó secundário quando um desastre total é declarado e o comando cf forcetakeover –d é utilizado para virar todo o storage para o site secundário.
A seguir é descrito o que acontece com cada configuração do parâmetro:
Configuração Padrão (cf.takeover.change_fsid on)
- Os volumes terão um novo file system ID (FSID) de forma a evitar conflito com os volumes originais
- LUNs (iSCSI ou FCP) terão um novo número serial (em parte derivado do FSID)
- NFS exports necessitam ser remontados no cliente
- LUNs ficam off-line de forma que somente as LUNs desejadas sejam colocadas online. Exemplo para trazer uma LUN online:
lun online /vol/vol1/lun0
- Do ponto de vista dos hosts os datastores deverão ser reescaneados.
- A razão para que as LUNs sejam colocadas off-line é evitar conflito de LUN ID.
Configuração Alternativa (cf.takeover.change_fsid off)
- opção disponível a partir da versão 7.2.4 do Data ONTAP
- A opção configurada em off permite que o FSID original seja preservado
- Isso permite que as LUNs mantenham o número serial original
- Os exports NFS também mantem o FSID original
- Volumes e pontos de montagem podem ser trazidos online automaticamente
Desabilitar a opção de change_fsid pode criar um takeover transparente para os clientes, porém há risco de perda de dados que poderia ocorrer no seguinte cenário:
- A interconexão de HA entre dois storages é interrompida. Nesse caso, ambos os nós continuam operacionais.
- Os dados de clientes escritos nos plexes locais e remotos ficam dessincronizados
- Se na sequência um desastre completo ocorrer em um site e o comando cf forcetakeover –f for realizado os plexes remotos estarão dessincronizados e poderá ocorrer perda dos dados escritos nos plexes do site original.
- Se a opção change_fsid estiver como ON, os clientes são forçados a remontar seus volumes e poderão fazer verificação de integridade dos dados antes de prosseguir com o processamento dos dados.
Próximo artigo da série: MetroCluster de A a Z (6 de 12): Hardware-assisted Takeover
Referências
Esta série de artigos utiliza como referências os seguintes documentos da Netapp, além de testes realizados nos equipamentos do laboratório do Agility Tech Center:
- System Administration Guide for 7-Mode (versão 8.2 do Data ONTAP)
- High Availability and MetroCluster Configuration Guide for 7-Mode (versão 8.2 do Data ONTAP)
- Network Management Guide For 7-Mode (versão 8.2 do Data ONTAP)
- Best Practices for MetroCluster Design and Implementation (TR-3548)
 Entre em Contato
Entre em Contato