








Neste artigo, falaremos um pouco sobre como surgiu a necessidade de se utilizar balanceamento de carga de servidores e com isso garantir a alta disponibilidade ideal para as aplicações e serviços, inclusive, a sofisticação adotada pelo hardwares dedicados.
Sobre Balanceamento de Carga
O objetivo do balanceamento de carga é criar um sistema que virtualize o trabalho dos servidores físicos que executam aqueles serviços. Uma definição mais básica é a de equilibrar a carga entre vários servidores físicos que atendem uma demanda específica, e com isso, fazer com que eles trabalhem de tal forma que aparente ser um grande servidor para o mundo externo.
Há muitos motivos para se fazer isso, no entanto, os principais pontos podem ser resumidos em escalabilidade, alta disponibilidade e previsibilidade. A escalabilidade é a capacidade de adaptação fácil e dinâmica ao aumento da carga, sem impacto sobre o desempenho atual. A virtualização de serviços oferece uma oportunidade interessante para a escalabilidade. Se o serviço no ponto de contato do usuário estivesse separado do servidor, o reescalonamento do aplicativo significaria apenas adicionar mais servidores, que não seriam visíveis ao usuário final.
Onde tudo começou
Nos primeiros dias da internet comercial, muitos bilionários do “ponto.com” descobriram um sério problema em seus planos de extensão. Os primeiros Mainframes não rodavam aplicações de servidores web e o máximo que se tinha de acesso – na época – era um hardware padrão totalmente limitado.
Os utilizadores da TI nem imaginavam o tamanho do problema que teriam no momento que publicassem algum serviço num único servidor, e posteriormente liberasse o acesso ao público.
HA??? O que é isso???
No início dos tempos da internet, era o DNS quem fazia este papel
Antes de existir qualquer outro dispositivo para balanceamento de carga, comercialmente dito, foram feitos muitos testes com tecnologias existentes – na época – para atingir as metas de disponibilidade e escalabilidade.
Veja um exemplo:
O método utilizado no início da internet para balanceamento e disponibilidade era o DNS (Round-Robin). O qual inclusive é usado até os dias hoje.***
[O Sistema de Nomes de Domínio (DNS) é o serviço que traduz nomes compreensíveis (www.exemplo.com) em endereços IP utilizados pelas máquinas. O DNS também fornece um modo pelo qual cada pedido de resolução de nome pode ser respondido com múltiplos endereços IP e em ordem diferente].
Qual era o problema, segundo os especialistas da época? Um servidor baseado em um único hardware jamais conseguirá gerenciar o tráfego que seria gerado por aplicações ou serviços existentes naquele momento, logo, se ele fosse desativado, o resultado seria a falência financeira.
Felizmente, alguns desses especialistas tinham planos, que inclusive, iria render muito dinheiro e ainda resolver exatamente este problema.
E dessa forma, surgiu o mercado de “Balanceamento de Carga”.
Como nem tudo é perfeito, surgiram os primeiros problemas

Imagem 1 – Exemplo DNS e Falha de host
- Perceberam que balancear / escalar os servidores não era tão eficiente assim…
- Clientes reclamando constantemente!!! Hora funcionava, hora não!
- Lentidão…
A solução via DNS Round-Robin não melhorou por muito tempo a disponibilidade. Isso devido ao DNS não ter a capacidade de monitorar a saúde os servidores. Logo, se algum desses se tornasse indisponível e consequentemente um usuário tentasse acessá-lo (antes mesmo que os administradores descubrissem o problema e o removessem do pool) o usuário poderia obter um endereço IP para um servidor não funcional.
Além disso, os usuários normalmente costumam armazenar (em cache) as resoluções de nome via DNS. Isso significa que nem sempre consultam um novo endereço IP e simplesmente voltam para um servidor que usaram anteriormente (esteja este funcional ou não).
Então, foi preciso INOVAR
A solução de DNS (Round-Robin) acabou desencadeando várias necessidades adicionais para a área de balanceamento de carga.
E mediante isso, decidiram que um “Balanceador de Carga” ideal precisaria ter:
· Capacidade de detectar automaticamente as falhas dos servidores;
· Ser responsável por tomar uma ação de contorno de forma transparente aos usuários num momento de falha dos servidores;
· Não enviar mais tráfego para um servidor com problemas;
· Notificar aos administradores, dentre outras;
[A previsibilidade é a capacidade de ter um alto nível de confiança no conhecimento ou previsão do direcionamento do usuário ao servidor. Embora esteja relacionada ao balanceamento de carga em comparação à distribuição não controlada, ela é centrada na idéia de persistência. A persistência é o conceito de garantir que um usuário não seja redirecionado pelo balanceamento de carga para um novo servidor após o início de uma sessão, ou quando o usuário retoma uma sessão previamente suspensa];
Essa é uma questão muito importante que o DNS (Round-Robin) não pode consegue endereçar.
Melhorias do Balanceamento de Carga
Baseado em software,surgiu o “IP-Cluster”;
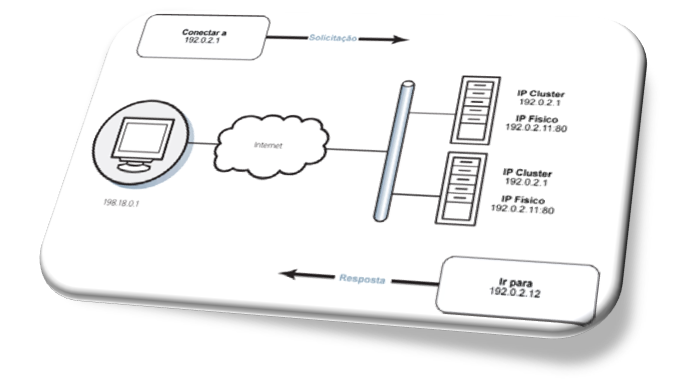
Imagem 2 – Exemplo de IP-Cluster
Quando um usuário tentava se conectar ao serviço ou aplicativo, na verdade se conectava ao “IP-Cluster” em vez do endereço IP real do servidor final. Qualquer um dos servidores do cluster que respondesse primeiro à requisição iria redirecioná-lo para um endereço IP físico (dele próprio ou de outro sistema no cluster) e a sessão de serviço então seria iniciada.
Um dos principais benefícios dessa solução é que os desenvolvedores de aplicativos da época poderiam usar várias informações para determinar com qual servidor o cliente deveria se conectar.
Por exemplo, eles poderiam fazer que cada servidor no cluster mantivesse uma contagem de sessões que cada membro do cluster já estava atendendo, direcionando novos pedidos para um servidor menos utilizado.
A maioria das soluções da época eram baseadas em truques de rede. No entanto, feita por desenvolvedores e chumbando tal solução numa determinada aplicação ou para um ambiente especifico. Algo caseiro mesmo, onde cada empresa tinha uma solução de balaceamento de carga diferente da outra.
Inicialmente, a escalabilidade dessa solução “IP-Cluster” era óbvia. Tudo o que você tinha de fazer era montar um novo servidor e adicioná-lo ao cluster, aumentando assim a capacidade do seu aplicativo!
No entanto, porém, contudo, todavia
Porém, com o tempo, a escalabilidade do balanceamento de carga baseado em aplicativos começou a gerar dúvidas. Como os membros do cluster precisavam manter contato constante uns com os outros para decidir quem aceitaria a próxima conexão, o tráfego de rede entre os membros do cluster aumentou exponencialmente a cada novo servidor adicionado ao cluster.
Depois que o cluster crescia até um certo tamanho (normalmente, de cinco a dez hosts), esse tráfego começou a criar impacto nos usuários finais, bem como na utilização do processador dos próprios servidores. Portanto, a escalabilidade era ótima, desde que você não precisasse exceder um número pequeno de servidores (menos do que o DNS Round-Robin poderia suportar).
- Com isso, a confiança do adquirida mediante a solução IP-Cluster começou a declinar de novo exatamente como aconteceu com o DNS Round-Robin.
- Cada ciclo de características inteligentes que habilitavam causava impacto;
- Os truques de rede utilizados para balanceamento de carga começaram a ficar complexos;
- Na época, conseguiam agregar cerca de até 10x servidores em um Cluster;
Era hora de mudar novamente
Devido aos problemas apresentados e limitações da solução em software, no caso IP-Cluster, dentre outras, finalmente surgiram os “hardwares” para Balanceamento de Carga – Baseado em REDE.
Balanceamento de Carga feito em HW
- Foi a segunda geração do balanceamento de carga de finalidade específica – Surgiu na forma de dispositivos baseados em rede;
- Esses dispositivos eram neutros em relação aos aplicativos, logo, poderiam exercer sua funcionalidade em qualquer ambiente;
Em síntese, esses dispositivos ofereciam um endereço de “servidor virtual” para o mundo exterior e quando os usuários tentavam se conectar, eles encaminhavam a conexão ao servidor verdadeiro mais apropriado, fazendo uma tradução de endereços de rede (NAT) bidirecional.
[Estes são os verdadeiros avós dos “Application Delivery Controllers” atuais!!!];
Modelo exemplo de Balanceamento de Carga feito em HW:
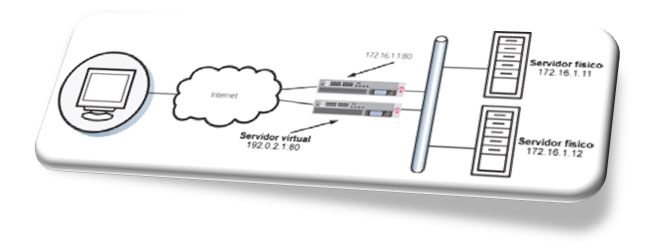 Imagem 3 – Exemplo de Balanceamento de Carga feito em HW
Imagem 3 – Exemplo de Balanceamento de Carga feito em HW
O Balanceador de Carga poderia controlar exatamente qual servidor receberia qual conexão e usava monitores de estado de complexidade crescente para garantir que o servidor de aplicativos estava respondendo conforme necessário.
Não era incomum uma companhia substituir o balanceamento de carga via software por uma solução baseada em hardware e notar imediatamente uma grande queda na utilização dos servidores, tornando desnecessária a compra de servidores adicionais a curto prazo e gerando um maior retorno do investimento ao longo prazo.
Com esta solução:
A Escalabilidade só era limitada pela capacidade do equipamento de balanceamento de carga e das redes conectadas ao mesmo;
Reduziu a sobrecarga da rede e dos servidores, liberando capacidade adicional de processamento aos servidores;
A alta disponibilidade também foi dramaticamente reforçada por uma solução baseada em hardware – O dobro da quantidade de dispositivos eram necessários para alcançar o máximo de benefícios da solução;
E assim, as coisas começaram a andar de fato… J
Por fim, este Tech-Tip teve como objetivo colaborar com informações as quais visam enriquecer o conhecimento de seus leitores. Contamos um pouco da história sobre como surgiu a necessidade do Balanceamento de Carga para servidores e assim pretendemos seguir continuamente para os próximos tópicos ligados a este assunto.
Abaixo segue o link com referência:
>>> No próximo artigo, vamos falar um pouco sobre a revolução dos “hardwares” de Balanceamento de Carga para os atuais ADCs (Application Delivery Controllers).
 Entre em Contato
Entre em Contato