








O Agility Tech Center realizou testes simulando falhas em seu laboratório de MetroCluster. Esse artigo discute uma simulação de falha completa do storage principal como em uma declaração de desastre real.
O teste de DR do MetroCluster executado no laboratório do Agility Tech Center simula a perda total do storage do site principal através do desligamento simultâneo da controladora ATC-NAP-A e das shelves do lado A na topologia mostrada na figura abaixo:
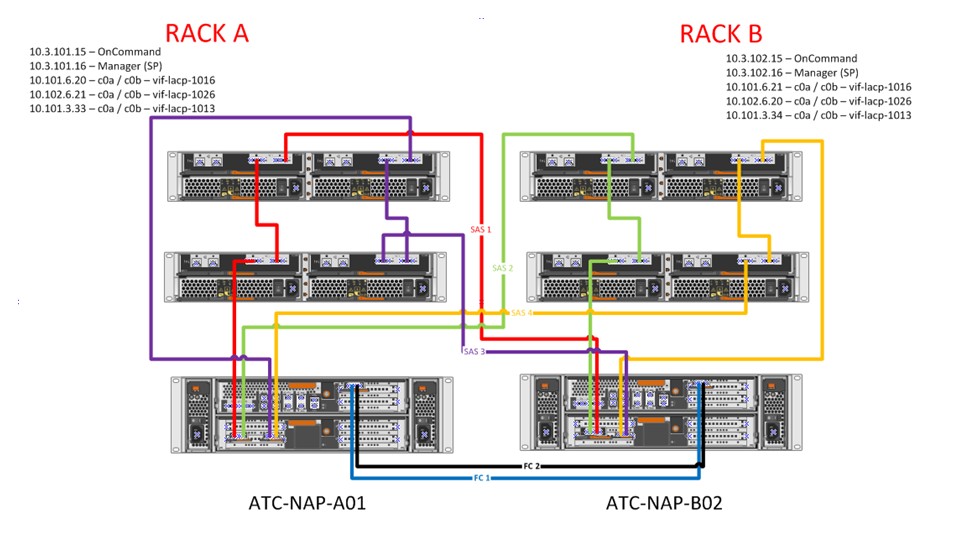
O artigo MetroCluster de A a Z (4 de 12): Configurações Básicas e de Rede, descreve em detalhes a topologia do laboratório do ATC e as configurações de failover utilizadas.
A controladora ATC-NAP-A precisa ser desligada antes das shelves A e o processo de desligamento tanto da controladora quanto das shelves precisa ser muito rápido para simular o desastre total do site A e possibilitar que o takeover seja manualmente declarado através do comando cf forcetakeover -d na controladora ATC-NAP-B.
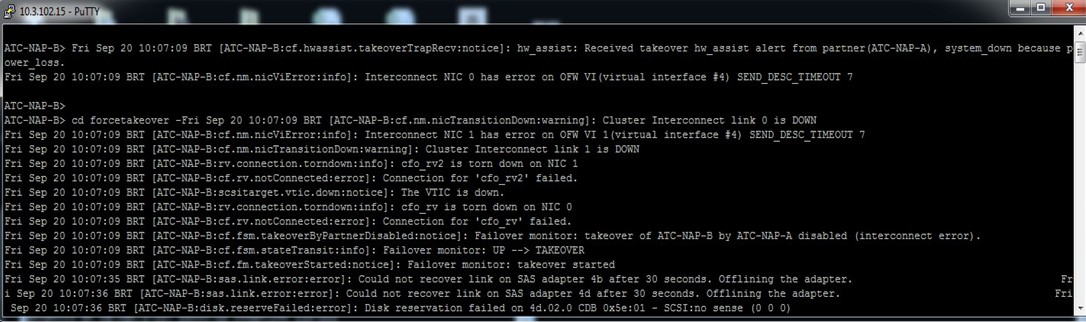
A imagem a seguir mostra o início dos logs na controladora ATC-NAP-B no momento da falha (início da mensagem, falha percebida pelo componente de hardware_assist takeover):
A seguir há o log da falha das shelves A, também da perspectiva do ATC-NAP-B:
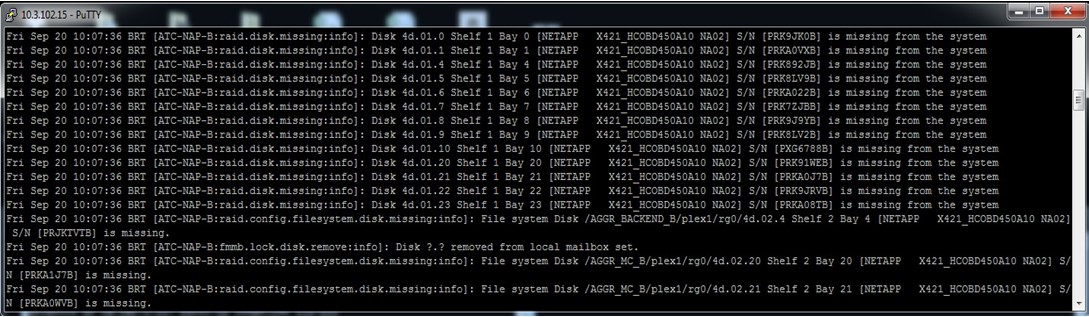
O recorte da imagem a seguir mostra que o ATC-NAP-B não pode diferenciar a falha total do storage A de uma falha da interconexão HA entre as controladoras (comportamento esperado para evitar o cenário de split brain) e, portanto, desabilita o takeover automático para que o desastre possa ser verificado e declarado manualmente.
NOTA: há como automatizar esse processo através de um terceiro site funcionando como mediador através da funcionalidade de MetroCluster Tie-Breaker (MCTB), porém esse processo não é escopo deste documento.

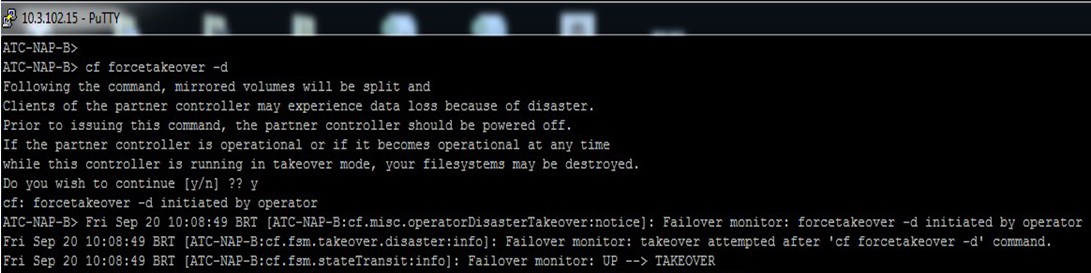
A imagem a seguir mostra a execução do comando cd forcetakeover -d no ATC-NAP-B:
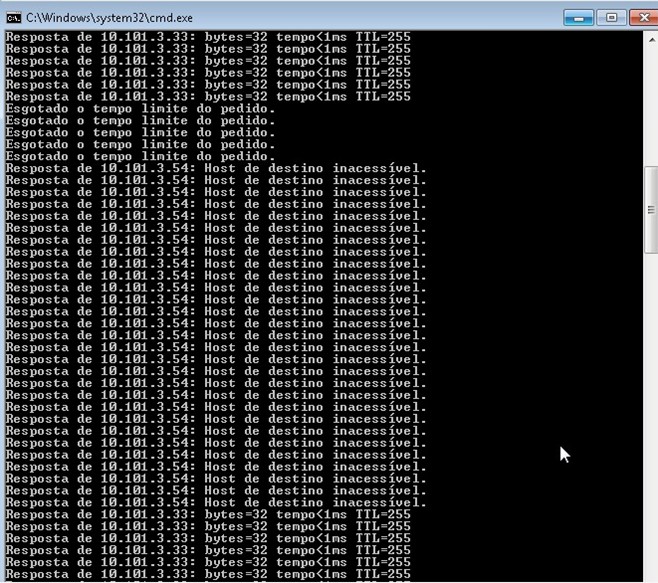
Como o teste foi executado em laboratório, a declaração do desastre ocorreu alguns segundos após o desligamento do storage A. O comando ping para o IP da controladora em falha a partir de uma VM hospedada no mesmo storage dá uma ideia do tempo gasto no processo:
A imagem a seguir mostra os datastores dos hosts ESX do rack A que não precisaram ser escaneados após o forced takeover, uma vez que a opção change_fsid está em off, permitindo que os volumes subam do lado sobrevivente com o mesmo ID:
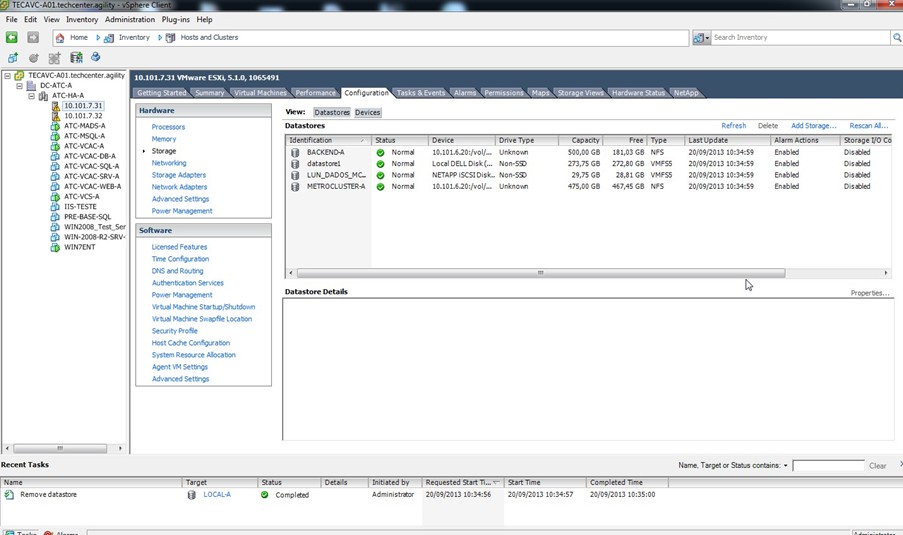
NOTA: A utilização da opção change_fsid ON ou OFF depende da arquitetura de DR pretendida. Maiores detalhes sobre essa opção podem ser obtidos no artigo MetroCluster de A a Z (5 de 12): MetroCluster – Parametrização de Failover e Giveback.
A figura a seguir mostra a saída do comando aggr status no nó emulado. Os aggragates do MetroCluster A não são mais mostrados como espelhados (não há a palavra “mirrored” no status dos aggregates):

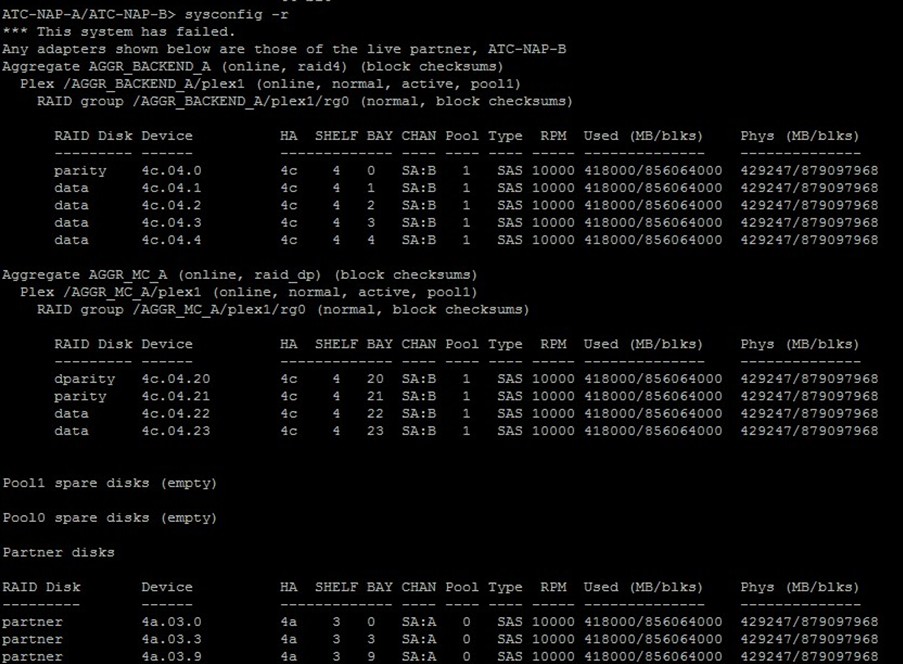
A figura a seguir mostra a saída (resumida) do comando sysconfig -r no nó emulado com os discos das shelves B (shelves 3 e 4) servindo os dados do MetroCluster A:
Os processos para o retorno da operação para o site principal após a correção da falha estão descritos no artigo MetroCluster de A a Z (12 de 12): Retorno do Teste de Disaster Recovery.
Próximo artigo da série: MetroCluster de A a Z (12 de 12): Retorno do Teste de Disaster Recovery
Referências
Esta série de artigos utiliza como referências testes realizados no laboratório do Agility Tech Center e os seguintes documentos da Netapp:
- System Administration Guide for 7-Mode (versão 8.2 do Data ONTAP)
- High Availability and MetroCluster Configuration Guide for 7-Mode (versão 8.2 do Data ONTAP)
- Network Management Guide For 7-Mode (versão 8.2 do Data ONTAP)
- Best Practices for MetroCluster Design and Implementation (TR-3548)
 Entre em Contato
Entre em Contato